

De ontwikkeling van Quayside, een braakliggend terrein van 12 hectare aan de rand van het centrum van Toronto, is een perfect voorbeeld van hoe informatietechnologie aan de invloed van het stadsbestuur dreigt te ontsnappen. Vorig jaar besteedde ik aandacht aan de rol van Sidewalk Labs (een zusterbedrijf van Google) in dit project. Ik was verheugd over de stedenbouwkundige aanpak en het uitgebreide proces van burgerparticipatie. Wel was ik verbaasd waarom Google interesse had om projectontwikkelaar te worden en er bovendien 50 miljoen Canadese dollar voor uit te trekken (nu weet ik waarom). Daniel Doctorow, de CEO van Sidewalk Lab, stelde me gerust met de verklaring dat de realisatie van een mensgericht stadsontwerp voorop staat en niet technologie: Expect very little of the value we create is about technology[1].
Het bleek dat ik te goedgelovig was. Maar laten we bij het begin beginnen.
In maart 2017 deed Waterfront Toronto, een ontwikkelingsmaatschappij in eigendom van de overheid, een oproep om voorstellen in te dienen om het oude havengebied van Toronto te transformeren in een sustainable mixed-use, mixed-income neighborhood. Sidewalk Labs diende een 200-pagina’s omvattend plan in voor een nieuw soort stad: Modular, dynamic wooden carbon-negative buildings that could easily be adapted to new uses, affordable housing, subterranean utility channels, outdoor spaces for walking and biking and designed to minimize the impacts of bad weather. Public transport and self-driving cars instead of private cars take care of transportation[2].De burgers van Toronto zouden worden betrokken bij een gezamenlijk planningsproces dat een jaar zou duren, met live gestreamde presentaties, rondetafelgesprekken, workshops en een zomerkamp voor kinderen.

Sidewalk deed geen moeite om te verbergen dat zijn belangstelling verder ging dan Quayside en het gehele 800 hectare grote havengebied betrof. Het bedrijf kondigde ook aan dat het gebied from the Internet up zou worden ontwikkeld mede met behulp van ubiquitous sensing. Volgens waarnemers zou het gebied de grootste sensor- en cameradichtheid ter wereld krijgen. Waterfront Toronto geloofde een partner te hebben gevonden die niet alleen wilde investeren, maar ook in staat was om het ultieme voorbeeld van een smart city te ontwikkelen[3]. Uitgangspunt – zo dacht men – was dat de beoogde dataverzameling ten doel had om de belangrijkste smart city functies te ondersteunen. Voorbeelden die daarbij werden genoemd waren:
- smart metering om het elektriciteitsverbruik te verminderen en de distributie van elektriciteit te optimaliseren
- Displays met real time informatie over aankomst- en vertrektijden van de beschikbare transportopties.
- Sensoren om verkeers- en voetgangersstromen, alsmede CO2-emissies te meten, mede om het effect van verkeer-beperkende maatregelen te testen.
- Sensoren ten behoeve van een geautomatiseerd systeem voor afvalinzameling.
- Een digitaal platform voor gezond eten, ontspanning en stimuleren van de band met de buurt.
- En meer van dit soort aantrekkelijke zaken.
Vanwege de directe band met gewenste smart cityfuncties, leek de gewenste dataverzameling onproblematisch, te meer daar Sidewalk Labs sympathiseerde met het principe van privacy by default. Dit betekent dat mensen niet om bescherming van hun persoonlijke gegevens hoeven te vragen maar dat hier als vanzelfsprekend in wordt voorzien. De verwachting was dat dataverzameling nooit zou resulteren in gepersonaliseerde profielen van inwoners.
Toen Ann Cavoukian, die al 16 jaar werkzaam was als de commissaris van de provincie Ontario voor informatie en privacy, adviseur werd van de raad van bestuur van Waterfront Toronto, wekte dat het nodige vertrouwen, hoewel velen zich bleven afvragen hoe Sidewalk Labs (lees Google) zijn geld wil verdienen.

In de loop van het afgelopen jaar stak er in Europa, de VS en Canada een groeiend verzet op tegen de ongebreidelde dataverzameling door giganten als Google, Facebook en Amazon. Facebook werd beschuldigd van het schenden van privacywetten en staat in de VS een enorme boete te wachten. Ook Google moet inmiddels miljarden aan boete betalen aan de EU.
De database van Google bestaat uit gepersonaliseerde profielen van vele honderden miljoenen mensen, inclusief hun daadwerkelijke locatie en financiële positie. Het bedrijf verdient ontzettend veel geld door data te verkopen aan vele duizenden marketeers op elke plaats op aarde. Data waarmee ze potentiële klanten direct kunnen benaderen met aantrekkelijke voorstellen om te voldoen aan latente materiële of spirituele behoeften. Details werden openbaar gemaakt door inside-stories van voormalige werknemers[4]. Het raffinement én het effect van de invloed die marketeers op onze gedachten en ons gedrag proberen uit te oefenen, stemt tot nadenken.
Een wetenschappelijk rapport van Douglas C. Schmidt, hoogleraar Computer Science aan de Vanderbilt University, onthult welke gegevens Google verzamelt en hoe[5]. Vooral gebruikers van Android en Chrome zijn een makkelijk doelwit, ook als ze hun telefoon niet actief gebruiken. Onderstaande illustratie toont de informatie die Google in één dag heeft verzameld van één specifieke persoon. Na de publicatie van het rapport gaf Google geen commentaar op de inhoud ervan, maar volstond met de geloofwaardigheid van de auteur in twijfel te trekken: “Dit rapport is ……. geschreven door een getuige voor Oracle in hun lopend geschil met Google over copyright. Het is dus geen verrassing dat het zeer misleidende informatie bevat. ” Prof. Schmidt antwoordde dat hij meer dan twee jaar geleden eenmalig was uitgenodigd als getuige-deskundige in het proces van Oracle versus Google inzake eerlijk gebruik van copyrights[6].
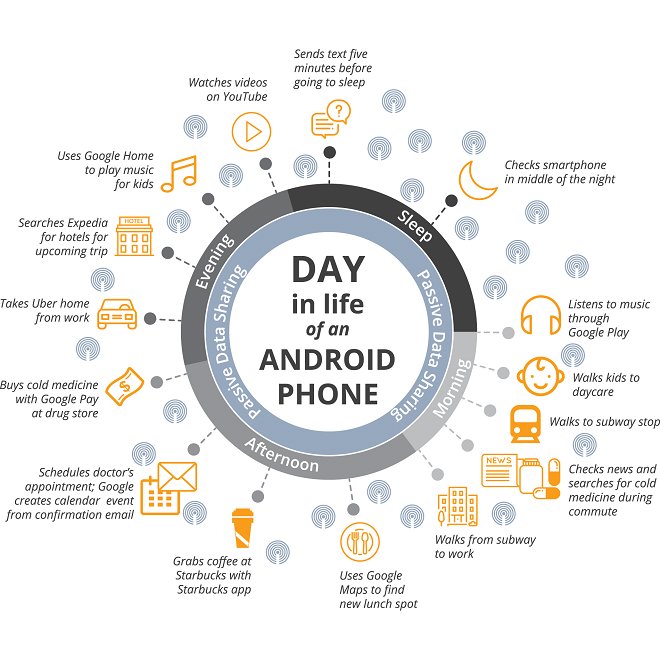
Publicaties als voornoemd geven inzicht in wat Sidewalk Labs zou kunnen bedoelen met development from the Internet up en ubiquitous sensing. Ook Ann Cavoukian was geschokt; ze zei: Once people’s interests and comings and goings are [tracked], it would be a nightmare. In haar hoedanigheid als adviseur van de raad van bestuur van Waterfront Toronto vroeg Cavoukian om een eenduidig verbod op het verzamelen van persoonlijke gegevens. Een belofte die Sidewalk Labs zei niet te kunnen doen, waarna ze zich terugtrok, samen met een aantal andere adviseurs.

Tijdens een persoonlijke ontmoeting schoof mijn Canadese collega, de politicoloog Blayne Haggart, de puzzelstukjes van de betrokkenheid van Google in elkaar[7]. Sidewalk Labs wil een ‘digitale laag’ bouwen over Quayside met behulp van een robuuste verzameling API’s (application programming interfaces). Deze stellen ontwikkelaars in staat om toepassingen te maken ten behoeve van inwoners en bedrijven. Hoe groter de hoeveelheid en de diversiteit van de te verzamelen gegevens hoe groter de inkomsten voor Sidewalk Labs zijn. Dit verdienmodel dat volledig aansluit bij de kernactiviteiten van Google, is nooit expliciet gemaakt. Het verklaart wel waarom Sidewalk Labs onmogelijk afstand kon nemen van het gebruik door derden te personaliseren gegevens.
De gretigheid van Google om betrokken te worden bij de ontwikkeling van smart cities heeft niets te maken met affiniteit met stedenbouw, noch met het creëren van smart city ‘gadgets’ zoals adaptieve verlichting, ondergronds afvaltransport of energie-neutrale huizen. Het belang van Google is ubiquotous sensing van het leven van de bewoners om zijn al enorme verzameling gepersonaliseerde profielen uit te breiden met real-time kennis van waar mensen zijn, wat ze willen of doen. Daarmee worden geïnteresseerde bedrijven voor veel geld voorzien van bruikbare marktinformatie. Bovendien ligt het in Sidewalk Lab’s bedoeling om zusterbedrijven, zoals Waymo (autonome taxis) een belangrijke rol te laten spelen in de herontwikkeling van het havengebied van Toronto[8].
Als Sidewalk Labs niets anders was geweest dan een projectontwikkelaar met de ambitie om een smart city te bouwen, deed het bedrijf tot nu toe goede dingen. Het zou een passende beloning hebben gekregen voor zijn werk voor Quayside en zou zeer waarschijnlijk ook betrokken worden bij de rest van Waterfront Toronto. Maar dit is niet de reden waarom Google Sidewalk Labs heeft opgericht.
De eerste les die steden kunnen leren van Quayside, is de noodzaak van expertise met betrekking tot databeheer en om van daaruit regels te formuleren voor de samenwerking met commerciële partijen[9]. Een stadsbestuur moet ondubbelzinnig voorschrijven hoe gegevens worden verzameld, gebruikt en beheerd. Het bestuur van Toronto Waterfront en het stadsbestuur van Toronto hebben dit overduidelijk nagelaten.
De tweede les is dat alle plannen voor stadsontwikkeling moeten expliciteren hoe deze bijdragen aan de levenskwaliteit van de burgers, en waarom de verzameling van bepaalde data daarbij een middel is. Niets minder, niets meer[10].
[1]http://smartcityhub.com/governance-economy/googles-sidewalk-labs-takes-the-lead-in-smart-city-development-in-toronto/
[2]Molly Sauter: Google’s Guinea-Pig City: Will Toronto turn its residents into Alphabet’s experiment? The answer has implications for cities everywhere. https://medium.com/the-atlantic/googles-guinea-pig-city-e022e50aa7d
[3]Sidney Fussel: City of the Future Is a Data-Collection Machine https://medium.com/the-atlantic/the-city-of-the-future-is-a-data-collection-machine-b06e0b9a1dba
[4]Hier is de eerste aflevering van een reeks: https://medium.com/s/story/the-complete-unauthorized-checklist-of-how-google-tracks-you-3c3abc10781d
[5]https://bloximages.newyork1.vip.townnews.com/wsmv.com/content/tncms/assets/v3/editorial/f/1b/f1bc6c94-a539-11e8-905a-136f4f930796/5b7bff66f1d7a.pdf.pdf
[6]https://phys.org/news/2018-11-google-scrutiny-digital-privacy.html
[7]Blayne Haggard & Zachary Spicer: Infrastructure, Smart Cities and the Knowledge Economy
Paper ten behoeve van de conferentie Making the smart city safe for citizensop 28 en 29 november, 2018 te Heerlen (Open Universiteit).
[8]https://medium.com/radical-urbanist/googles-next-big-product-the-city-de642eefc369
[9]https://stadszaken.nl/smart/gebiedsontwikkeling/1953/is-de-slimme-stad-straks-van-google
[10]Zie mijn overzicht van uitdagingen voor stadsbesturen om een humane stad te ontwikkelen: http://smartcityhub.com/collaborative-city/long-read-beyond-the-smart-city-challenges-for-a-humane-city/








